
Closing the Reliability Gap

Engineering Foundations for Credible Predictive Maintenance in Digital Asset Ecosystems
Prognostic Health Monitoring (PHM) and IoT-enabled asset monitoring are largely promoted as cornerstones of today’s modern reliability strategies. However, in practice, many such monitoring system implementations fall short of delivering consistent operational value to the organization. The issue is rarely the lack of sensor data or analytical tools or capabilities. But, most of the times, it comes down to something not evident but far more critical. It is the absence of a solid engineering foundation.
AI assisted predictive maintenance only becomes credible when it is built on reliable data, proper contextualization, and a clear link to maintenance execution. Without these elements, it is very difficult even for the most advanced analytical solutions to translate into meaningful outcomes to the organizations.
From a fundamental engineering standpoint, the starting point is obviously not the algorithms, but it should be the data quality and the context. IoT systems generate large volumes of high frequency data such as flow rate, temperature, and pressure, but these channels if looked at without much context would give very little signals. In the real world scenarios, equipment behavior is heavily influenced by operating conditions such as load variations, duty cycles, environmental factors, utilization patterns, etc. If these are not properly captured and linked to the streamed data, it becomes very difficult to distinguish between variations in normal operational and early signs of degradation. From the implementations I have done for different types of equipment, I have noticed that this is where many implementations begin to lose credibility.
Another common gap is the weak integration link between condition monitoring data and maintenance system that have all the history of asset maintenance stored. From the maintenance systems, work orders, equipment failure codes, repair records, and asset hierarchies provide a lot of contexts needed to interpret the predictive signals. However, in many cases, this data is inconsistent or poorly structured. Equipment failure codes are either too generic to use or not consistently used by the technicians at all when capturing the failure details in the CMMS. Also, work order closure with critical data capturing lacks discipline. Asset hierarchies are not configured in CMMS with the failure modes and physicals systems along with their interactions in mind, which sometimes renders the data not so useful for analysis. Without the component level traceability, it is very much impossible to connect condition indicators to actual failure mechanisms.
Multiple systems are used for coordinating the prediction ecosystem and the system alignment is another area where practical challenges occur. Identifying the assets itself is often different across IoT platforms, operational systems, and CMMS databases. Time stamps of the real time data stream are not always synchronized thereby making it difficult to accurately correlate sensor trends with maintenance events. Additionally, raw sensor data typically requires preprocessing such as filtering noise from the data, normalizing the signals, and extracting meaningful features. When these steps are not carefully defined or looked at, the output might look sophisticated from a data science perspective who designs the predictive algorithms, but the results will remain ambiguous to engineers and maintenance teams.
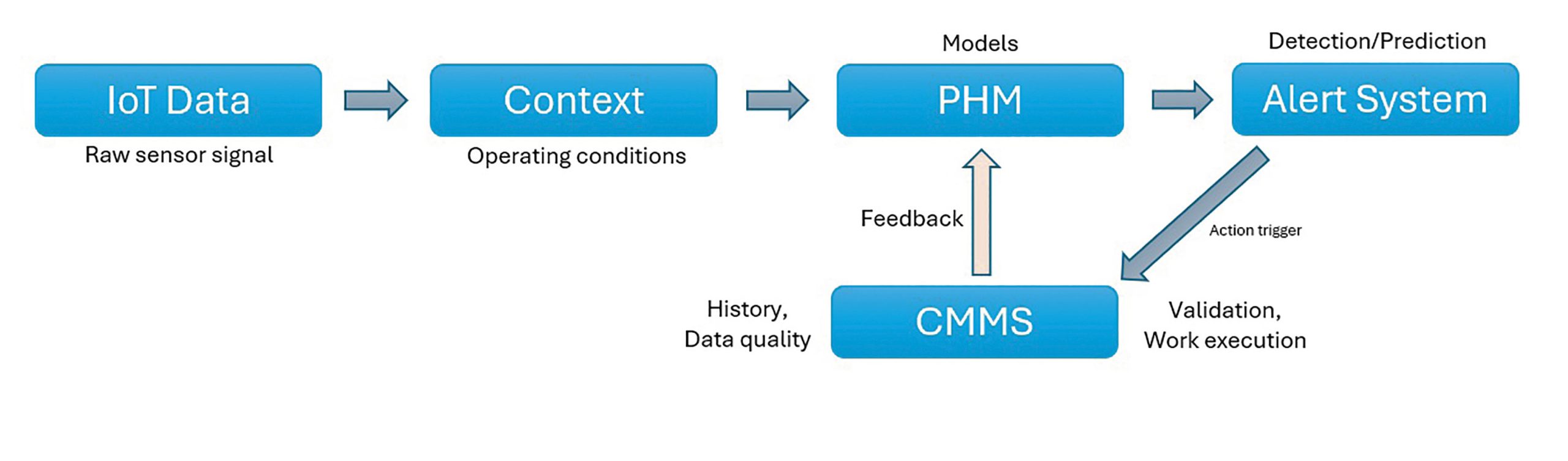
From what I have noticed repeatedly from working on multiple different deployment projects, data governance in general is often underestimated. It clearly plays a key role in determining whether a predictive maintenance systems succeeds or fails. Poor data quality in the CMMS such as missing asset records or attributes, inconsistent inspection records, unclear asset structures, etc. directly impact the reliability of the PHM models. What will definitely help is establishing clear ownership of data, enforcing validation rules with in the CMMS system, and maintaining standard failure reporting practices. In reality, the accuracy of the predictive models is more about the data governance principles than the fine tuning of algorithms itself.
With all the necessary precautions taken care of and a robust predictive algorithm development ecosystems is built, the organizations would expect the predictive systems to work efficiently.
However, in many cases, there is a struggle at the last mile which is execution. Alerts from PHM systems do not create value on their own. They need to be converted into actionable work within the existing maintenance workflows. This requires clear prioritization of the alerts based on asset criticality, failure severity, and alignment with replacement planning and scheduling processes.
One big challenge I encountered when initially trying to have the ground team to start using the predictive systems was the mistrust, they had development after seeing a couple of false alerts. If technicians and planners cannot easily interpret or trust these alerts, they are unlikely to act on them.
For instance, consider rotating equipment such as a centrifugal pump deployed in the field. When the equipment data is streamed through the IoT systems, vibration data alone may indicate abnormal behavior. But the accuracy of the prediction can be better only when it is tied to historical failure patterns and operating conditions. When this connection is established, early signs of bearing degradation can be identified with enough confidence to plan field interventions. In cases where this has been done well, the results are tangible with fewer unexpected failures and better MTBF.
A key differentiator to the successful implementation of the predictive monitoring systems is the presence of a feedback loop. When a predictive alert gets translated to maintenance action, the outcome must be captured methodically and reviewed. Specifically, was the prediction accurate? did the intervention address the root cause? are similar patterns emerging elsewhere? etc. Key success metrics such as mean time between failures, false positive alarm rates, and prediction accuracy allow the teams to continuously refine both the models and the maintenance strategy.
Without this closing loop the accuracy of the models cannot be validated and improved leading to gradual loss of trust with the maintenance team.
In essence, predictive maintenance is not just an analytics problem. It is an engineering and operations problem. Teams that focus just on the sensors and algorithms often struggle, while those that invest time and effort in developing proper data structure, system integration, and execution discipline tend to see real benefits of the predictive systems. PHM and IoT technologies can be powerful enablers, but only when they are built on a foundation that connects data, context, and action in a consistent and practical way.
Text: Rajaram Madhavan Picture: Rajaram Madhavan
Rajaram Madhavan

Rajaram Madhavan is a Maintenance Business Systems and Digital Asset Management professional in the oil and gas services sector, with over 17 years of experience, specializing in enterprise asset management systems, reliability analytics, and Asset Performance Management. He has led several initiatives involving CMMS platforms, maintenance data analytics, and operational data integration to improve equipment reliability and asset lifecycle performance. His work focuses on integrating maintenance data, operational telemetry, and analytics frameworks to support predictive maintenance and reliability engineering practices. Rajaram holds a master’s degree in mechanical engineering from the Georgia Institute of Technology, USA.



Subscribe to the free Maintworld newsletter here!

Latest






