
Lighthouse for Europe’s Railways

A think tank that influences decisions. A lighthouse that guides the sector. Professor Uday Kumar wants the EFNMS Railway Maintenance Committee to become both, at a time when Europe’s railways must deliver more with infrastructure that is already ageing.
Europe’s railways are expected to carry more people, reduce emissions and keep societies moving on infrastructure that is decades old. Beyond its operational role, railway infrastructure is a critical backbone for Europe, supporting not only passenger and freight transportation, but also strategic resilience, including military mobility and crisis response. This elevates maintenance from a technical function to a matter of European security, reliability, and continuity of service
Professor Uday Kumar believes the next leap will not come from technology alone, but from how well the sector transforms data, competence and collaboration into maintenance solutions that passengers never notice
Uday Kumar is not new to big systems and or high expectations. Born in India and based in Sweden for four decades, he has spent 35 years in academia focused on maintenance, led a railway research centre for more than two decades, advised government agencies and spoken in the Swedish parliament about the state of railway network in Sweden and how maintenance can improve them. His career has crossed mining, oil and gas, aviation and rail. The pattern he sees is reassuring and demanding at the same time: most of what makes maintenance work is universal, but each sector presents its own domain-specific challenges.
That combination of breadth and specificity is exactly what he wants to bring to his current role as Chairman of the EFNMS Railway Maintenance Committee, a position he took on in May 2024. His ambition is blunt: to build a committee that becomes a recognised European voice in railway maintenance, one that decision-makers listen to when setting investment priorities.
The creation of the EFNMS Railway Maintenance Committee reflects a clear need at European level. Railway systems are no longer purely national infrastructures, but interconnected networks where maintenance challenges extend beyond domestic boundaries. While organisations such as UIC, UNIFE and ERA play important roles in the railway ecosystem, EFNMS contributes a complementary perspective focused on maintenance practice, knowledge sharing, and cross-sector experience.
“The vision is to become a think tank,” he says. “When we talk, the sector and policy makers listen.” But vision is only half the job. Kumar describes the committee’s mission with a powerful metaphor: it should function as a lighthouse.
A lighthouse does not do the sailing. It does not move the ship. It does not replace the crew. It guides, especially when the conditions are difficult.
Kumar’s difficult conditions are familiar across Europe: ageing railway infrastructure and rolling stock, growing demand for rail travel, climate-related disruptions, and a shortage of people with deep railway engineering competence. Add to that the practical reality of distributed assets. A factory can be maintained in one place. A railway is a network spread across long distances, where the repair itself might take minutes but reaching the fault can take hours.
This is why he keeps returning to a world that has become central in recent years: resilience. Failures will happen. The competitive edge is how quickly the system recovers, how fast faults can be detected, diagnosed and fixed without cascading delays and disruptions.
In Kumar’s view, the committee’s work must start with a roadmap for integrating new technologies into maintenance in a way that is seamless and operationally robust.
“The promise of AI, digitalisation and advanced monitoring is real, but railways cannot afford isolated pilot projects that disrupt operations. Technology must fit the work, not the other way around”, he stresses.
He also highlights a second theme that is both technical and political: extending the life of existing infrastructure. Much of Europe’s railway network is already built. Rebuilding it is slow, expensive and material-intensive. Life extension, done intelligently, supports both performance and sustainability by reducing material consumption and aligning with broader climate and resource goals.
New technology, he argues, provides maintenance teams with deeper insight into infrastructure health, sometimes into what cannot be seen directly. Better monitoring of degradation and remaining useful life enables decisions that are more data-driven: what to maintain, when, and why. The challenge is to ensure that these insights are effectively translated into timely and actionable maintenance decisions. It also enables a shift from reactive maintenance to planned interventions that safeguard availability. This reinforces condition-based predictive maintenance as a core capability for modern railway systems.
Availability is the point where maintenance becomes visible to the public. Kumar frames it as a simple but demanding triad: railways must be attractive, affordable and available.
“Maintenance is not the only factor, but it is often the hidden constraint. The more trains you run, the less time you have for maintenance windows. The tighter the timetable, the greater the impact of any failure.”
That is also why he stresses maintenance logistics and supply chains. Resilience is not only about use of new technologies, sensors and analytics, it is all about spare parts availability, access to the right competence, and the ability to respond even when global disruptions make procurement harder. In a networked system, the weakest link is often not the failure itself, but the time it takes to restore it.
Kumar is enthusiastic about AI, but he is careful with the language. He compares it to fire: useful if handled well, destructive if handled carelessly. AI should not replace humans, he says. It should enhance human performance and decision-making capability.

“I concerned about “lazy thinking”: outsourcing reflection and judgement to tools that can respond quickly but not always wisely.”
He makes a distinction that many organisations still blur. Digitisation is converting information into digital form. Digitalisation is enabling automatic information flow and more autonomous decision-making. Digital transformation is a fully interconnected, seamless and prescriptive system, where you can understand a train’s problem in real time from another city and know what action to take.
Railways, he says, are not there yet.
The Railway Maintenance Committee’s challenge is therefore not to celebrate technology, but to guide adoption: human-centric AI, Industry 4.0 with an Industry 5.0 mindset, and integration that strengthens rather than fragments work processes.
Yet Kumar is candid about where the committee stands today. Progress has been slower than he wanted.
“Building a European committee is not like leading a single research centre with a clear mandate and budget. Stakeholders have different incentives, different cultures and different constraints.
Some potential members have had to step back due to internal limitations.”
A roadmap with milestones has been the goal, but even he admits the timeline is tight. Still, he calls himself an “eternal optimist” and his optimism is not naïve. It is operational. He has seen systems change, and he knows that maintenance improvements often arrive as a delayed effect: foundational work first, visible impact later.
One of his strongest Kumar’s warnings is about competence. As experienced railway engineers retire, organisations sometimes replace deep domain knowledge with general digital skills. Computer science competence is valuable, but it cannot substitute for understanding how physical railway systems behave.
“Technology will not solve everything,” he says. “They are only tools.”
For him, the next decade will bring more digitalisation in maintenance, but the critical question is whether the sector can also rebuild its education pipeline and make railways attractive as a career.
Someone still must design, build and maintain the physical world.
His advice to young professionals is direct: focus on intelligent maintenance solutions that reduce time and cost. The opportunity is large because the need is growing. Infrastructure is ageing, demand is rising, and the climate case for rail is stronger than ever. Maintenance is no longer a backstage function: it is a strategic capability.
A lighthouse needs a fleet
A lighthouse is only effective when ships use its guidance. Kumar’s message to the sector is that maintenance excellence cannot be achieved by isolated optimisations. It requires a European-level conversation, shared roadmaps, shared standards and shared learning across operators, infrastructure managers, industry, academia and policy. Standardisation will be a critical enabler. EFNMS
Railway Maintenance Committee will actively engage with CEN and ISO to contribute to current and future railway maintenance standards, ensuring that best practices are translated into harmonised, implementable frameworks across Europe.
In other words: not just better maintenance, but a stronger maintenance community that can steer together when conditions become challenging.
EFNMS Railway Maintenance Committee is a step in this direction
Text: Mia Heiskanen



Subscribe to the free Maintworld newsletter here!
Lubrication management needs a reset

Good lubrication is still one of the most important ways to protect assets, cut waste and improve reliability. Yet in many plants, the basics are slipping.
Lubrication management rarely makes headlines. It is not the shiny part of maintenance that attracts new talent, budgets or conference stages. But on the shop floor, it is often the difference between stable production and recurring, expensive surprises.
That perspective is shaped by years spent close to work. Technical Advisor Aleksi Nykänen has built his career around lubrication management and condition monitoring, first inside large industrial operations and later in customer-facing development work. Technical Manager Mika Römpötti brings decades of hands-on experience across lubrication roles and long-term involvement in professional lubrication networks and industry guidance. They have seen what “good” looks like in mature organisations, and how quickly standards can erode when competence, ownership and routines are not protected.
Two Interflon specialists, Technical Advisor Aleksi Nykänen and Technical Manager Mika Römpötti, describe a pattern they keep seeing across industries: lubrication is treated as a routine task, not as a controlled process. The result is a long list of small, avoidable mistakes that accumulate into major reliability problems.
“People don’t necessarily lack effort. They lack a system,” Nykänen says. “Lubrication management is a wide, multi-part discipline. If the basics aren’t defined and controlled, everything becomes reactive.”
In practice, the issues start with fundamentals: storage, handling and cleanliness. Lubricants are exposed to dirt and moisture, containers are not clearly separated, and the same equipment may end up with multiple incompatible greases. Even when someone is “doing the rounds,” the lubricant may not reach the contact surfaces as intended.
A common visual tells the story: grease around the nipple and on surrounding surfaces, but not necessarily where it is needed. The environment gets messier, contamination increases, and the next lubrication cycle adds more dirt to the same area. It can feel like work is being done, yet the asset is being set up for failure.
Over-lubrication is another recurring theme. Without calculation and clear standards, manual lubrication, automatic or semi-automatic lubricators can deliver far more than required. Excess grease increases heat and drags, pushes past seals, attracts contaminants and creates a housekeeping problem that hides early warning signs.
“If you don’t calculate the right amount, you’re guessing,” Römpötti says. “And guessing often means too much.”
The consequences are not theoretical. Industry sources often cite that a significant share of premature bearing failures is linked to poor lubrication practices and contamination. When plants struggle with cost pressure and productivity targets, it is hard to justify waste that is both preventable and recurring. Yet the root causes are rarely about one bad decision. They are structural.
One factor is the loss of tacit knowledge. Many experienced technicians have retired, and their practical know-how did not transfer into documented standards, training or role definitions. In some organisations, it is not even clearly described what competence is expected from a person responsible for lubrication tasks.
“If you haven’t defined what ‘good’ looks like, how can you ensure the next person can deliver it?” Nykänen asks.
Another factor is education. Lubrication engineering is not widely covered in many technical programmes, and it is not perceived as an attractive speciality for young professionals. The result is a gap between the complexity of modern assets, and the training people receive before entering the field.
Then there is prioritisation. Many organisations talk about predictive maintenance, digitalisation and advanced analytics, but still operate in “firefighting mode.” Preventive routines are squeezed, and lubrication becomes a checkbox rather than a reliability lever. Without the real ownership of lubrication program, it is hard to get lubrication and the culture on the level where it should be.
The specialists are not anti-technology. They use condition monitoring, oil analysis energy consume measurements and existing customer data as part of improvement work. But they are sceptical of the idea that AI can “solve lubrication” if the underlying practices are inconsistent.
“AI can help you predict failures,” Römpötti says. “But it won’t go out there and fix the basics. If the fundamentals are poor, prediction just tells you what you already set in motion.”
There is also a less discussed contributor: equipment design and delivery. Even new machines often arrive without features that make lubrication control practical, or possible such as proper sight glasses for checking oil levels.
“When the only way to verify a level is to remove a plug, every inspection becomes a contamination risk”, Nykänen states.
Maintenance teams are then left with impossible instructions: check the oil level weekly, but do it without a safe, visual method. In the real world, the task is skipped, rushed or done in a way that introduces more dirt.
So, what does improvement look like when the goal is not to sell a product, but to change outcomes?
The approach described by Nykänen and Römpötti starts with a simple principle: do not begin in the deep end. First, make the basics visible and measurable: cleanliness, correct lubricant selection, correct quantities, correct intervals, correct tools and clear responsibilities. After the field is corrected, next step is to correct the content of tasks in the maintenance system.
Their work often begins on site, walking through assets with the people who perform lubrication tasks. The goal is to identify the most critical gaps and fix what is preventing good practice. Sometimes that means reorganising storage and labelling. Sometimes it means adding small hardware upgrades that reduce contamination risk and make inspection realistic. Sometimes it means harmonising lubricant portfolios that have grown uncontrolled over time.
“We want the frontline to succeed,” Nykänen says. “Not to create dependency on an external expert, but to build capability inside the plant.”
This is where training becomes less about classroom theory and more about empowering technicians to make decisions. The wins can be surprisingly small: a leaking gearbox that stops leaking without a major rebuilding, or a lubrication team that finally feels their work is recognised as critical.
“One of the best moments is when people thank you for listening,” Römpötti says. “They feel their work matters again, and then they start improving it themselves.”
The bigger message is uncomfortable but necessary: lubrication management is not a side task. It is an operational discipline that needs standards, competence, tools and leadership attention.
Plants that want higher reliability often invest in sensors, dashboards and analytics. Those investments can pay off, but only if the physical reality is under control. Cleanliness, correct lubrication and clear practices are not old-fashioned. They are prerequisites.
And perhaps that is the most thought-provoking part: the future of maintenance may be digital, but the future of reliability still depends on people doing the basics well.
The hidden cost of “good enough” lubrication
Poor lubrication is rarely a single mistake. It is usually a chain: contamination, wrong product, wrong quantity, and missing routines. The result shows up as repeat failures, wasted energy, and maintenance work that never seems to end.
• Lubrication errors and contamination can account for up to 30% of technical disturbances and around 40% of maintenance costs.
• Excess friction and wear can drive unnecessary energy use. With better lubrication practices, energy consumption linked to friction and wear could be reduced by about 10%.
Source: Interflon
If those numbers feel high, ask a simpler question: how many of your recurring issues are truly “mysterious” once you look at lubricant cleanliness, correct quantities, and basic inspection access?
Lubrication management: a practical reset checklist
1. Define what “good” looks like: roles, competence expectations, standards
2. Control cleanliness: storage, handling, transfer, sealing
3. Harmonise lubricants: avoid uncontrolled product sprawl
4. Calculate quantities: reduce over-lubrication and waste
5. Make inspection safe: sight glasses, sampling points, practical access
6. Use data wisely: oil analysis and condition monitoring to support, not replace, basics
7. Build capability: train and coach the people who do the work
Text: Mia Heiskanen Photos: Interflon


Subscribe to the free Maintworld newsletter here!
Scaling Reliability: What INX International’s Journey Reveals About Sustainable Maintenance

A recent industry webinar highlighted a critical challenge for maintenance professionals: how to move from constant firefighting to building a long-term, sustainable reliability culture across multiple sites.
During the webinar, experts from INX International Ink Co., AssetWatch, and Noria Corporation emphasised that tools and technologies, while important, aren’t what ultimately drive success. The real differentiator is an organisation’s ability to align its people, processes, and daily discipline around reliability.
To better understand the impact of the transformation, Maintworld spoke with INX International about changes to the company’s daily operations.
INX International is a global manufacturer of inks and coatings for packaging, commercial, and digital printing. In high-volume production, such as metal decorating, consistent transfer, reliable curing, and stable operation are crucial to uptime. Any performance fluctuation affects the line and supply chain immediately.
INX launched its predictive maintenance strategy in 2023 with a focused pilot at its Charlotte site. Rather than implement tools everywhere, the team first established standard templates, clear asset structures, and consistent processes.
Building on support from digital platforms and condition-monitoring partners, the model was subsequently replicated across other U.S. sites in months.
A key step in this expansion was connecting real-time production data with condition monitoring systems to support maintenance decisions based on actual equipment behaviour. By integrating platforms such as AssetWatch for equipment condition monitoring and Oden for production data visibility, INX aligned maintenance activity with how equipment is running in real time.
“This approach moves maintenance from fixed schedules to interventions based on usage, load, and early wear indicators. Instead of servicing equipment by calendar, teams respond to measurable performance changes,” company officials said.
“In practice, this reduces unnecessary maintenance, improves response time to developing issues, and supports more stable operation across the production environment. A major advantage is the ability to identify early indicators of failure, allowing intervention before unplanned downtime impacts production.”
A central message of the webinar: reliability efforts fail if organisations focus on complex tools before establishing basic, consistent processes.
Many organisations introduce predictive maintenance tools, sensors, or analytics across different sites in parallel. While this can deliver short-term improvements, it often creates fragmentation. Different plants start working in different ways, using different definitions of failure, and measuring success differently. The speakers emphasised that standardisation is essential for successful transformation. This means defining key assets, identifying clear failure modes, and maintaining consistent practices across all sites.
This isn’t about restricting teams, but about creating a shared language. When everyone evaluates equipment consistently, improvements scale rather than being recreated at each site.
Establishing a foundation is essential; only then does it make sense to add advanced tools, such as vibration monitoring or predictive analytics. Otherwise, even the best systems struggle to deliver consistent results.
Turning data into action, not just dashboards, matters. Building on this, another key webinar theme was closing the gap between data collection and action.
Most organisations today are not short of information. Sensors, dashboards, and alerts are everywhere. Yet many still struggle with the same issue: data that is seen but not acted upon.
The webinar made a key point: data alone doesn’t improve reliability, action does. Value comes when teams respond swiftly and reliably to data, such as inspecting equipment early, adjusting lubrication, or scheduling preventive maintenance.
A strong indicator of maturity is response time. As organisations improve, they do not just collect more data, they react to it faster and with greater confidence.
Successful organisations treat data as a trigger for behaviour, not just information for review. When a system flags early signs of equipment degradation, the value lies not in the alert itself but in whether maintenance teams investigate, validate, and act on it in a timely manner. Over time, this creates ‘repeatable wins’: not isolated successes but steadily fewer unexpected breakdowns.
“The feedback loop trains the AI over time. As it learns, alerts become fewer and more refined, providing real signals amid the noise. It requires patience—many give up too soon—but persistence pays off,” says Borpit Intawiwat, Vice President, Engineering, INX International.
While processes and tools dominated much of the technical discussion, culture repeatedly emerged as the real deciding factor.
Reliability programs often fail not because technology is lacking, but because the organisation is not aligned. Maintenance, operations, and management may share goals but have different priorities and incentives.
“Even the best systems can’t overcome misalignment or lack of trust between teams,” one speaker said. As INX International’s VP of Operational Excellence, Chris Rodgers, told Maintworld: “You can install the best monitoring systems, but without alignment and trust between maintenance and operations, the impact remains limited.”
Reliability is ultimately about organisational culture, not just technology. INX’s focus was to use data for faster, better decisions—not simply to increase information. Reliability only improves when data leads to action. When maintenance and production teams share the same data and jointly interpret it, decisions become less reactive and more collaborative. Instead of debating opinions, teams can focus on what the equipment is indicating.
A further shift occurs when frontline teams use reliability tools proactively rather than waiting for instructions. This behavioural change—though small—often signals that reliability is now routine, no longer a separate initiative.
The webinar also touched on a common blind spot: reliability’s human side.
With more predictable maintenance, work environments change: emergency callouts drop, planned work rises, and stress falls. Technicians spend less time reacting and more time improving.
This shift directly affects work-life balance and job satisfaction. In some examples discussed, improved reliability allowed technicians to spend less time reacting to breakdowns and more time focusing on planned, value-added work. The result is not only operational improvement but also a healthier and more stable work environment.
Michael Patulski, Vice President, Paste Operations told Maintworld that recent system integrations and AI have boosted employee retention and streamlined recruiting at INX Charlotte. According to Patulski, AI drives employee development with targeted, real-time learning. These tools speed up new-hire competency, strengthen ongoing training, and accelerate career growth.
“AI has created advanced career paths and improved on-floor performance. INX Charlotte has seen logistics staff advance to frontline production supervision and machine operators move to production analytics. It’s exciting to witness accelerated career growth and high retention at INX Charlotte, Patulski concludes.
INX International
INX International is a wholly owned subsidiary of SAKATA INX worldwide operations, a $1.8 billion company established in 1896. The company is a global manufacturer of high-performance printing inks and coating for commercial, packaging, and digital print applications with full-service locations in North America, South America and Europe.
Lubrication: still the quiet failure point
Despite advances in monitoring technology, lubrication remains one of the most common—and preventable—causes of equipment failure, experts note.
The industry webinar Scaling Reliability with INX: Aligning People, Processes, and PdM, held on April 23, 2026, underscored a key insight: many lubrication failures stem not from poor-quality lubricants, but from contamination and inconsistent practices.
Dirt ingress, moisture, incorrect application, and poor storage practices continue to undermine equipment reliability—even in highly automated environments.
A structured lubrication program typically follows three steps:
1. Set clear targets – for example, cleanliness levels or contamination limits.
2. Define the right actions – such as improved storage, filtration, or application methods.
3. Measure consistently – through oil analysis and regular inspection.
What matters most is not the individual step, but the discipline of repeating the cycle. The speakers in the webinar also stressed that lubrication should not exist in isolation. When combined with vibration analysis, temperature monitoring, and other condition-based tools, it becomes part of a much more complete view of equipment health.
INX’s experience offers clear lessons for real-world reliability scaling:
• Focus on critical assets first –start where failure has the highest impact.
• Standardise early – build templates and shared structures before scaling.
• Invest in training continuously – not once, but repeatedly.
• Work with partners where it adds value – especially for specialised expertise.
• Make reliability shared ownership among operators, engineers, and maintenance teams.
Looking ahead, reliability systems are moving toward greater integration, bringing production data, condition monitoring, and maintenance management together rather than keeping them in separate tools.
The advantage is not increased complexity but less. Connected data lets teams spend less time searching and more time acting.
Text: Nina Garlo-Melkas Photos: INX International
Subscribe to the free Maintworld newsletter here!
Closing the Reliability Gap

Engineering Foundations for Credible Predictive Maintenance in Digital Asset Ecosystems
Prognostic Health Monitoring (PHM) and IoT-enabled asset monitoring are largely promoted as cornerstones of today’s modern reliability strategies. However, in practice, many such monitoring system implementations fall short of delivering consistent operational value to the organization. The issue is rarely the lack of sensor data or analytical tools or capabilities. But, most of the times, it comes down to something not evident but far more critical. It is the absence of a solid engineering foundation.
AI assisted predictive maintenance only becomes credible when it is built on reliable data, proper contextualization, and a clear link to maintenance execution. Without these elements, it is very difficult even for the most advanced analytical solutions to translate into meaningful outcomes to the organizations.
From a fundamental engineering standpoint, the starting point is obviously not the algorithms, but it should be the data quality and the context. IoT systems generate large volumes of high frequency data such as flow rate, temperature, and pressure, but these channels if looked at without much context would give very little signals. In the real world scenarios, equipment behavior is heavily influenced by operating conditions such as load variations, duty cycles, environmental factors, utilization patterns, etc. If these are not properly captured and linked to the streamed data, it becomes very difficult to distinguish between variations in normal operational and early signs of degradation. From the implementations I have done for different types of equipment, I have noticed that this is where many implementations begin to lose credibility.
Another common gap is the weak integration link between condition monitoring data and maintenance system that have all the history of asset maintenance stored. From the maintenance systems, work orders, equipment failure codes, repair records, and asset hierarchies provide a lot of contexts needed to interpret the predictive signals. However, in many cases, this data is inconsistent or poorly structured. Equipment failure codes are either too generic to use or not consistently used by the technicians at all when capturing the failure details in the CMMS. Also, work order closure with critical data capturing lacks discipline. Asset hierarchies are not configured in CMMS with the failure modes and physicals systems along with their interactions in mind, which sometimes renders the data not so useful for analysis. Without the component level traceability, it is very much impossible to connect condition indicators to actual failure mechanisms.
Multiple systems are used for coordinating the prediction ecosystem and the system alignment is another area where practical challenges occur. Identifying the assets itself is often different across IoT platforms, operational systems, and CMMS databases. Time stamps of the real time data stream are not always synchronized thereby making it difficult to accurately correlate sensor trends with maintenance events. Additionally, raw sensor data typically requires preprocessing such as filtering noise from the data, normalizing the signals, and extracting meaningful features. When these steps are not carefully defined or looked at, the output might look sophisticated from a data science perspective who designs the predictive algorithms, but the results will remain ambiguous to engineers and maintenance teams.
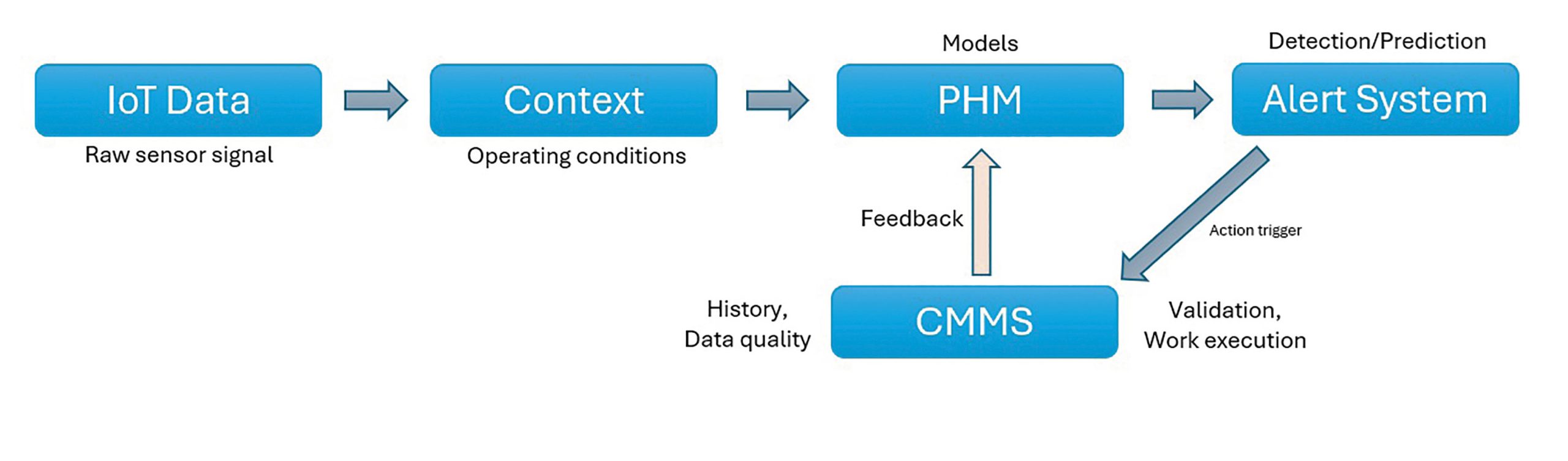
From what I have noticed repeatedly from working on multiple different deployment projects, data governance in general is often underestimated. It clearly plays a key role in determining whether a predictive maintenance systems succeeds or fails. Poor data quality in the CMMS such as missing asset records or attributes, inconsistent inspection records, unclear asset structures, etc. directly impact the reliability of the PHM models. What will definitely help is establishing clear ownership of data, enforcing validation rules with in the CMMS system, and maintaining standard failure reporting practices. In reality, the accuracy of the predictive models is more about the data governance principles than the fine tuning of algorithms itself.
With all the necessary precautions taken care of and a robust predictive algorithm development ecosystems is built, the organizations would expect the predictive systems to work efficiently.
However, in many cases, there is a struggle at the last mile which is execution. Alerts from PHM systems do not create value on their own. They need to be converted into actionable work within the existing maintenance workflows. This requires clear prioritization of the alerts based on asset criticality, failure severity, and alignment with replacement planning and scheduling processes.
One big challenge I encountered when initially trying to have the ground team to start using the predictive systems was the mistrust, they had development after seeing a couple of false alerts. If technicians and planners cannot easily interpret or trust these alerts, they are unlikely to act on them.
For instance, consider rotating equipment such as a centrifugal pump deployed in the field. When the equipment data is streamed through the IoT systems, vibration data alone may indicate abnormal behavior. But the accuracy of the prediction can be better only when it is tied to historical failure patterns and operating conditions. When this connection is established, early signs of bearing degradation can be identified with enough confidence to plan field interventions. In cases where this has been done well, the results are tangible with fewer unexpected failures and better MTBF.
A key differentiator to the successful implementation of the predictive monitoring systems is the presence of a feedback loop. When a predictive alert gets translated to maintenance action, the outcome must be captured methodically and reviewed. Specifically, was the prediction accurate? did the intervention address the root cause? are similar patterns emerging elsewhere? etc. Key success metrics such as mean time between failures, false positive alarm rates, and prediction accuracy allow the teams to continuously refine both the models and the maintenance strategy.
Without this closing loop the accuracy of the models cannot be validated and improved leading to gradual loss of trust with the maintenance team.
In essence, predictive maintenance is not just an analytics problem. It is an engineering and operations problem. Teams that focus just on the sensors and algorithms often struggle, while those that invest time and effort in developing proper data structure, system integration, and execution discipline tend to see real benefits of the predictive systems. PHM and IoT technologies can be powerful enablers, but only when they are built on a foundation that connects data, context, and action in a consistent and practical way.
Text: Rajaram Madhavan Picture: Rajaram Madhavan
Rajaram Madhavan

Rajaram Madhavan is a Maintenance Business Systems and Digital Asset Management professional in the oil and gas services sector, with over 17 years of experience, specializing in enterprise asset management systems, reliability analytics, and Asset Performance Management. He has led several initiatives involving CMMS platforms, maintenance data analytics, and operational data integration to improve equipment reliability and asset lifecycle performance. His work focuses on integrating maintenance data, operational telemetry, and analytics frameworks to support predictive maintenance and reliability engineering practices. Rajaram holds a master’s degree in mechanical engineering from the Georgia Institute of Technology, USA.
Subscribe to the free Maintworld newsletter here!
The Illusion of Control: Rethinking Risk in an Uncertain Maintenance World

A particular kind of silence precedes failure in complex systems—not inactivity, but the quiet hum of things apparently working as they should.
Indicators behave within expected limits, processes unfold without friction, and the system feels readable, as if its logic is fully captured and brought under control. Nothing appears to be wrong—and that is precisely the problem. It is a comforting illusion, one engineering has cultivated with remarkable success.
Yet systems rarely betray themselves in obvious ways. Failures begin not with rupture, but with deviation—small, almost imperceptible shifts. A parameter drifts, a delay emerges, a dependency changes. Individually, these signals appear harmless. Together, they form patterns that are difficult to perceive, especially when observation tools continue to confirm what we expect to see. As long as these remain consistent, the system appears stable. But consistency is not truth: a system may remain coherent while gradually detaching from the reality it is meant to describe.
Maintenance has long been tasked with preserving that coherence, and for a time it succeeded. But today’s systems extend beyond what can be observed, entangled with volatile supply chains, energy systems, and evolving constraints. Control becomes less a property and more a temporary alignment between expectation and reality—one where risk does not emerge suddenly, but grows silently until it can no longer be ignored.
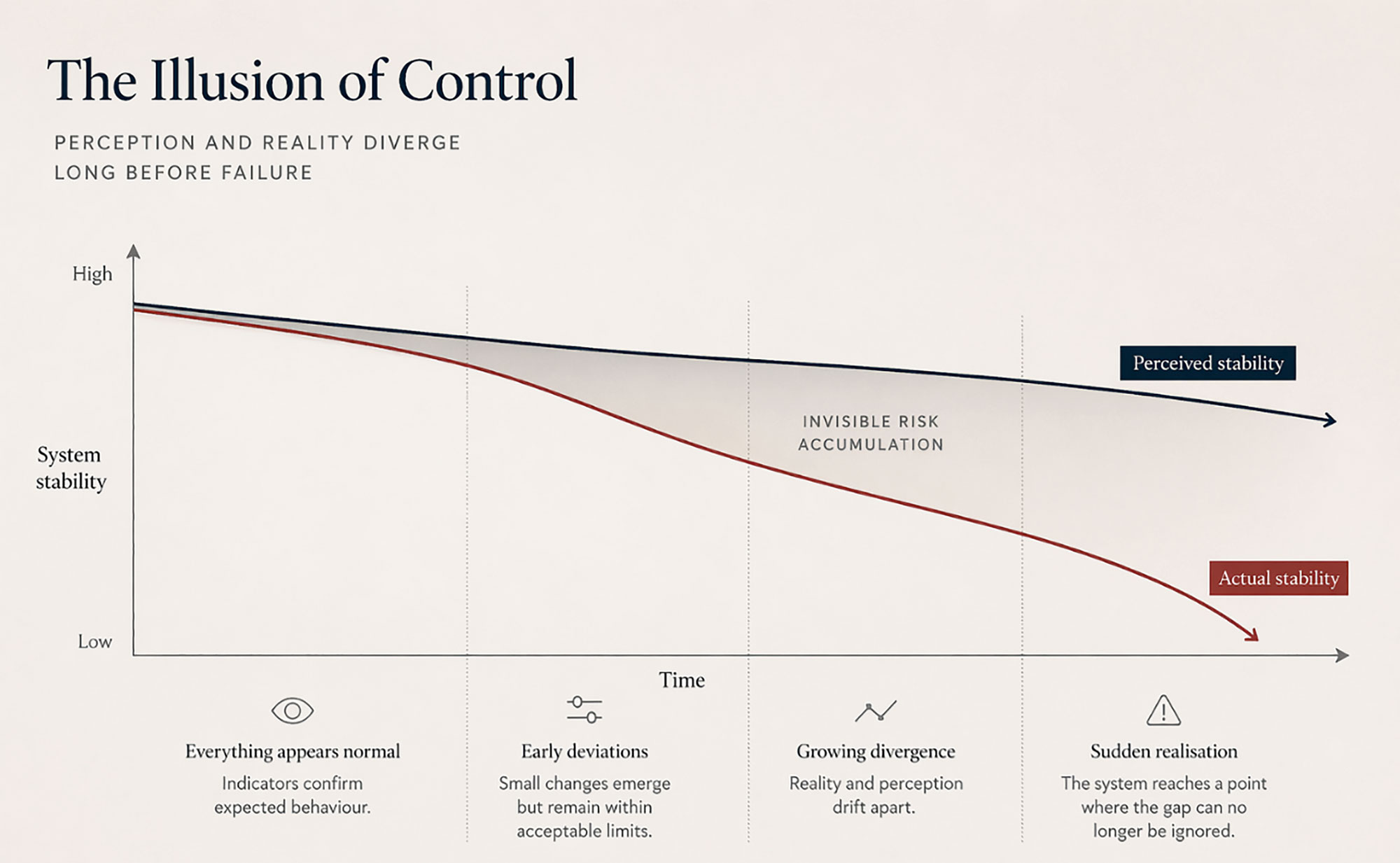
Legacy of Criticality: Maintenance has reinforced the illusion of control. It evolved to bring structure to uncertainty, transforming what once seemed unpredictable into something that could be classified and managed. The concept of criticality became one of its most important foundations. At its core, criticality offered a simple idea: not all assets matter equally. Some failures are negligible, others disruptive or costly. By ranking these differences, maintenance moved from reacting to failures to anticipating them, focusing effort where it mattered most. Criticality became the bridge between technical analysis and practical action, allowing organizations to allocate resources in a way that felt both efficient and justified.
For a long time, this approach worked remarkably well. In stable environments, where dependencies were understood, failure probability and consequence could be assessed with confidence. The system behaved within known limits, and maintenance strategies reflected that stability. But this stability was an assumption.
As the environment shifts, the assumption weakens. Assets once considered secondary can become critical—not because they change, but because the system around them does. A component gains importance when supply chains tighten, or processes lose their tolerance to disruption. Criticality does not disappear, but it becomes less stable. It no longer reflects an intrinsic property of the asset, but a relationship between the asset and an evolving context. When that context is not considered, decisions rely on assumptions that may no longer hold.
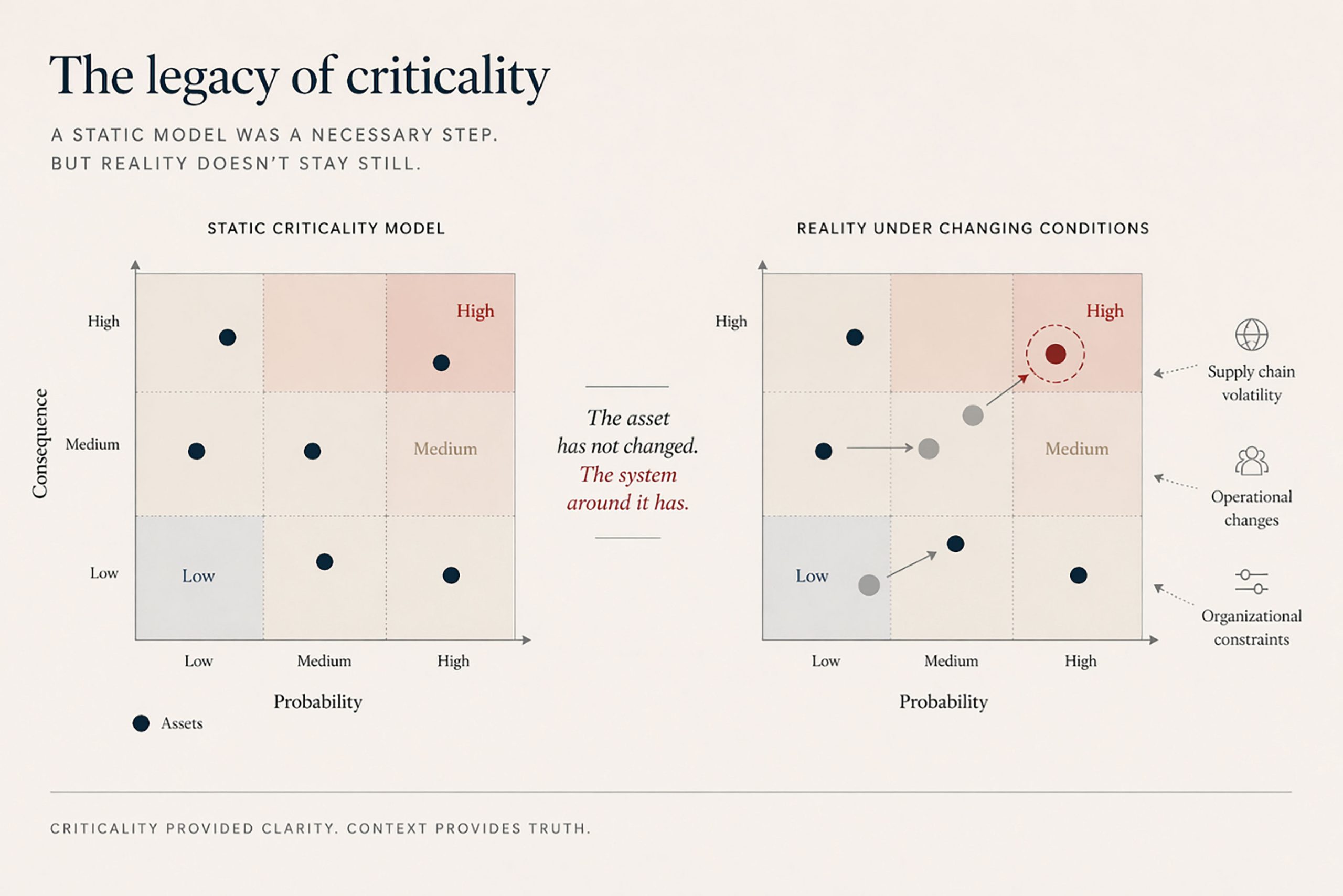
The concept itself is not flawed. It remains essential. But its traditional use implies a system that changes slowly, where priorities can be defined and periodically reviewed. What we now face is something different—a system in motion, where relevance is shaped not only by the asset, but also by its connections and dependencies.
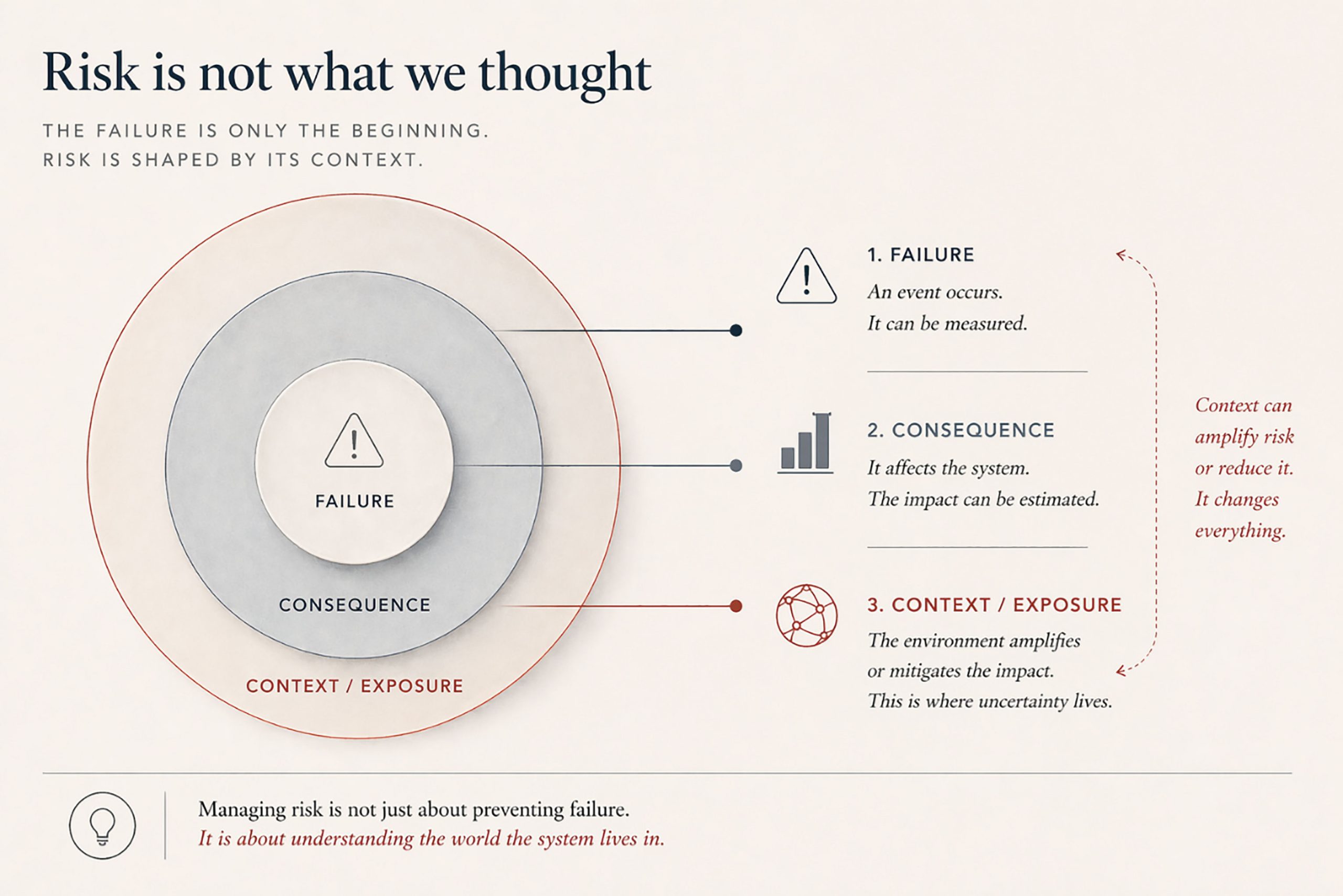
Risk Is Not What We Thought: For a long time, risk appeared to be a concept we had domesticated. It could be expressed, calculated, and compared—probability on one side, consequence on the other—yielding a measure that could be ranked and acted upon. There was a sense that uncertainty, once quantified, could be contained within rational decision-making.
To a certain extent, this was true—at least, within the world for which that logic was designed. But as systems become more complex and less stable, this formulation captures only part of what risk actually is. It describes the likelihood of an event and the scale of its impact, yet says little about the conditions that make that impact manageable or catastrophic.
For decades, the role of maintenance was clear: prevent failure, reduce downtime, and optimize cost within stable operating conditions.
In practice, the same failure can lead to very different outcomes. A component may fail under identical conditions, yet its impact can range from negligible to severe—not because the failure has changed, but because the system that receives it has. What was once absorbed without difficulty may now propagate across tightly coupled processes. The event is the same; the system is not. Risk, therefore, is not simply a property of the asset or the failure mode. It emerges from the relationship between them and the environment in which they exist. It is shaped by interaction, dependency, and timing. It is fundamentally contextual. Like in Solaris, the system cannot be understood in isolation from the conditions that shape it.
This does not invalidate the traditional definition, but it exposes its limits. Probability and consequence remain essential, but they are no longer sufficient. Another dimension drives risk: how exposed the system is, how capable it is of absorbing disruption, and how dependent it has become on elements beyond its control. In practice, this dimension is often sensed rather than formalized.
When a maintenance engineer prioritizes an asset not because it fails often, but because “if it fails now, we are in trouble,” what is being assessed is not just likelihood or impact, but vulnerability—the system’s ability to cope at that moment. The challenge is not to calculate risk more precisely, but to understand it more completely.
The System Fights Back: At this point, the system stops behaving as we expect it to. The complexity of industrial systems is both structural and relational. Technical components, human decisions, organizational processes, and external constraints form a network where causality is distributed rather than localized. Failures rarely stem from a single cause; they emerge from multiple conditions aligning in ways difficult to anticipate. This challenges the fundamental assumption in maintenance that understanding individual failure modes is enough to understand system behavior.
It is still necessary, but is no longer sufficient. The system cannot be fully explained by its parts, because interactions between those parts generate behaviors that do not exist at the component level. The human is part of the network. The interpretations and actions of operators and decision-makers shape how failures unfold—sometimes stabilizing the system, sometimes contributing to its degradation. The boundary between human and technical elements is not fixed, but continuously negotiated.
Maintenance models still focus on what can be measured—failure rates, repair times, condition indicators—but critical dynamics emerge in layers that are harder to capture: timing, coordination, perception. This does not make control impossible, but it redefines it. Control cannot be achieved through reduction and classification. It requires understanding how the system behaves as a whole, how interactions evolve, and how risk is distributed across the network.
No longer confined to components or failure modes, risk is embedded in the system’s structure and dynamics. Managing it requires moving beyond isolated events and recognizing the system as an active, evolving entity—one that does not simply respond to interventions, but reshapes them.
Data Are Not the Answer: When complexity increases, the instinctive response is to gather more information. Systems that are harder to understand are observed more closely, measured more extensively, and monitored through an ever-growing network of sensors. Over time, this has led to an expansion in visibility: patterns can be detected earlier, degradation tracked in real time, and interventions scheduled with increasing precision. In this sense, the system appears more transparent than ever before.
The real failure is not when an asset stops working, but when the system cannot respond in time—when the gap between expectation and reality becomes too wide to manage.
But this transparency can be misleading. Data reveal what is happening within the asset, but not necessarily what it means for the system as a whole. A signal may indicate a developing fault, but its significance depends on factors beyond the data itself—operational constraints, dependencies, and the system’s ability to respond. Data require interpretation to become useful. Without context and judgment, more information does not bring understanding closer. Paradoxically, while failures are detected earlier, responses remain constrained by frameworks designed for a different context.
This is not a failure of technology, but of interpretation.
When the signals of Condition-Based Maintenance, for example, are not integrated into a broader understanding of risk—one that includes context and exposure—their value is limited. They inform, but they do not transform. What emerges is a distinction between knowing more and understanding better. The former depends on data and infrastructure, the latter on how that information is framed and interpreted. In continuously evolving systems, data alone cannot provide stability—they can only reflect instability with greater precision.
Maintenance as Resilience: For decades, the role of maintenance was clear: prevent failure, reduce downtime, and optimize cost within stable operating conditions. But when those conditions change, the problem itself changes. In uncertain environments, the question is no longer simply how to avoid failure, but how to continue operating when it occurs in unexpected circumstances. The focus moves beyond prevention toward the system’s ability to absorb disruption, adapt, and recover without losing coherence—what we now understand as resilience.
A resilient system is not one that never fails, but one that does not collapse when it does. It continues to function, even under degraded conditions, without crossing into instability. The distinction reshapes the role of maintenance from doing the right things under expected conditions to doing the right things when those conditions no longer hold. Resilience introduces a temporal dimension, where decisions are not only about preventing failure, but also about how the system responds over time.
When dependencies fail or conditions shift, the question becomes whether the system can adapt without triggering further disruption. This requires flexibility—operational, organizational, and technical. Maintenance, in this sense, extends beyond assets. It becomes a capability that supports the organization’s ability to respond under uncertainty. Beyond reliability, decisions about maintenance influence continuity and performance over time.
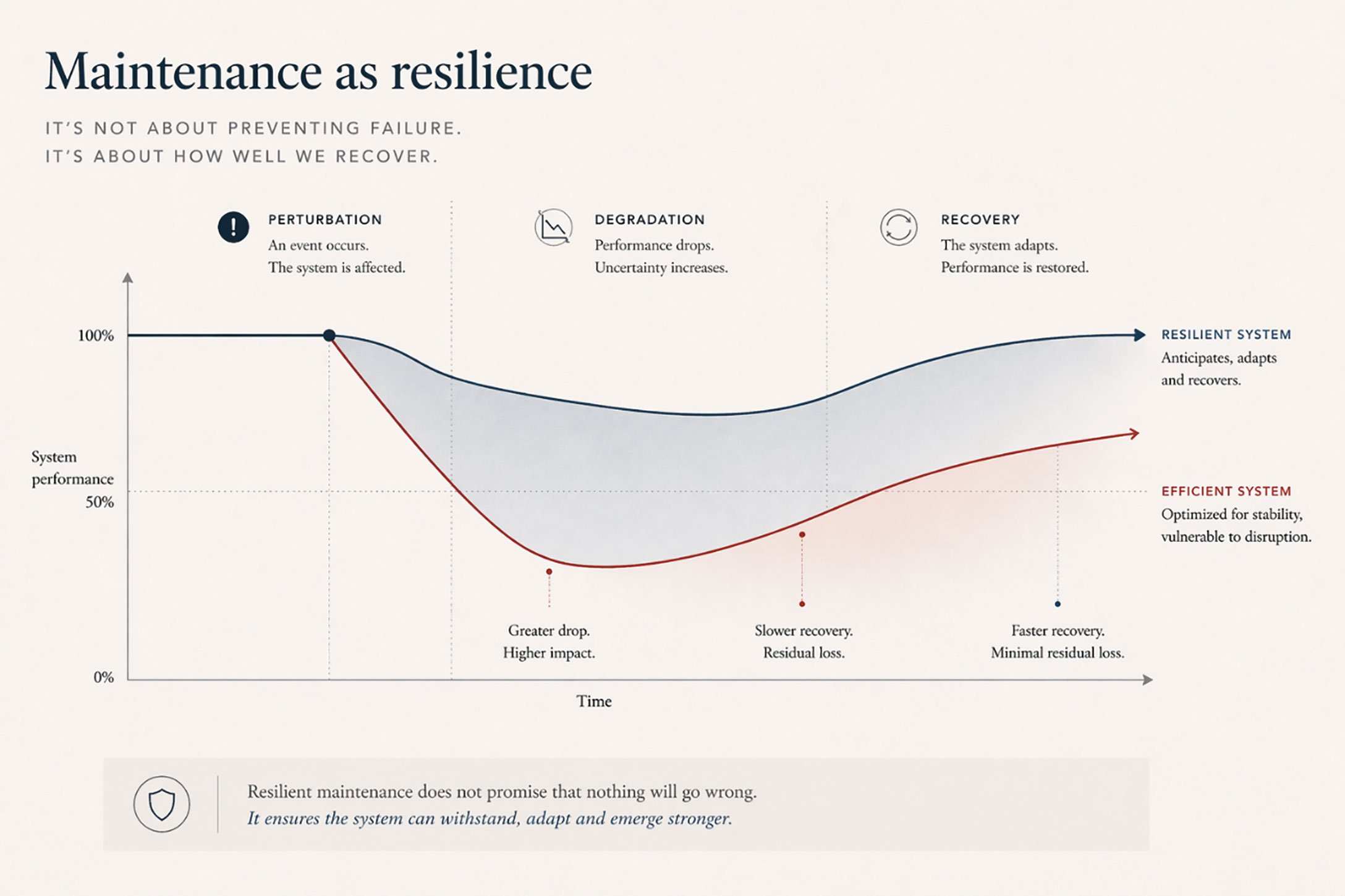
Systems optimized purely for efficiency may perform well under stable conditions, yet become fragile when conditions change. Resilience acts as a counterbalance, ensuring adaptability in the face of uncertainty. The challenge is to design systems that are both competitive and capable of enduring disruption.
A New Logic: If maintenance is to support resilience, the way risk is understood must also evolve. Not by discarding existing principles, but by extending them beyond the limits for which they were designed. Probability and consequence remain essential, but they no longer capture the full dynamics of how disruption unfolds. What has been missing is not another variable, but a recognition that the significance of failure depends as much on the state of the system as on the failure itself. The same event does not carry the same weight under different conditions. At times, the system can absorb disturbance; at other times, even minor deviations can trigger disproportionate effects. Therefore, risk can no longer be treated as a fixed attribute. It is a condition that evolves with the system, reflecting not only what might happen, but also how prepared the system is to respond. A likely failure may represent little risk if the system is resilient, while a rare event may become critical if exposure is high.
Admittedly, this perspective makes decision-making more demanding. It requires continuous interpretation, the ability to reassess assumptions, and the integration of information that does not fit neatly into predefined categories. Maintenance strategies can no longer be static; they must adapt as the system evolves. From a practical standpoint, it is not enough to ask how likely a failure is, or how severe its consequences might be in general terms. The relevant question becomes: what does this failure mean for the system, here and now?
Answering this requires more than data. It requires a framework that integrates context with analysis, bridging the gap between technical knowledge and operational reality. This is not a departure from established practices, but a reorientation. Reliability and condition monitoring remain essential, but their value depends on how they are connected and interpreted. Risk is no longer static, but dynamic—continuously shaped by the system it describes. In this connection between what the system is and what it is becoming, maintenance begins to act not as a technical function, but as a strategic capability.
The Real Failure: The world maintenance was designed for has quietly changed. The principles that once provided clarity remain valid, but the system they describe no longer behaves in the same way. Its boundaries have expanded, its dependencies have multiplied, and its behavior has become less predictable. In this landscape, the greatest risk is not failure itself, but the persistence of assumptions that no longer reflect reality. Systems are still managed as if conditions were stable, even as they continue to evolve. The meaning of failure shifts with the system, often without being fully recognized.
The more precise our tools become, the stronger the belief that uncertainty is under control. Yet the system reveals new forms of unpredictability—not because it is less understood, but because it is more interconnected and exposed to forces beyond its immediate structure. Control must be reconsidered, not as something that can be fully achieved, but as something that must be continuously negotiated. Maintenance is no longer about preserving stability, but about enabling the system to navigate change without breaking. This shift extends beyond the technical domain. It affects how decisions are made, how risk is perceived, and how efficiency is balanced with adaptability.
Failure itself does not disappear. What changes is its significance. The focus moves from the event to the system’s ability to absorb and respond to it. The real failure is not when an asset stops working, but when the system cannot respond in time—when the gap between expectation and reality becomes too wide to manage. This does not provide certainty, but a different perspective: one that accepts that systems evolve, risk is contextual, and control is always partial. Perhaps that is where the discipline must now position itself—not in the confidence of having mastered the system, but in the awareness of how easily that confidence can be misplaced. The difference is whether we question it in time—or only once it breaks. That silence is still there—just harder to recognize.
Text: Prof. Diego Galar
Photo: shutterstock
Subscribe to the free Maintworld newsletter here!
AI-Assisted Maintenance: What Changes, and Does Everything Change?
AI-assisted maintenance is moving from the theoretical to the practical, coming into use as an everyday tool as operators build up a level of trust. But what changes in maintenance work when artificial intelligence enters the picture, and what stays the same?
The short answer is that AI does not replace maintenance expertise; it helps the roles of technician, engineer or document controller, for instance, evolve by accessing relevant established, tried and tested guidance to support their tasks.
Maintenance professionals have long aimed to transition from reactive firefighting toward preventive and predictive approaches. As an accessible, intuitive tool, AI can accelerate that shift by finding patterns humans may miss, especially when data comes from multiple sources: condition monitoring, process data, work orders, spare parts history, and operator notes, for instance.
“The promise for now and in the future is simple: fewer surprises, increased efficiency in work planning, and empowered workers with easy access to right documents and data. Organizations have a clearer view of risk and where any uncertainties will come from,” said Risto Vuopala, Global Business Driver for Industrial Digital Software, ABB’s Process Industries division.
Predictive maintenance answers a familiar question: When is something likely to fail? Prescriptive maintenance goes a step further: What should we do about it, when should we do it, and what is the expected impact on risk, cost, and availability? “AI supports both, but only when it has access to reliable, contextual data,” Vuopala notes.
In day-to-day work, the most important change is not that machines suddenly “maintain themselves”. It is that maintenance teams spend less time searching for signals in noise and more time on decisions: diagnosing root causes, validating recommendations, prioritizing work based on production impact, and improving reliability practices.
“Maintenance becomes more proactive and data-driven, while need for the craft remains the same,” Vuopala said.
Expertise still matters. Machines still wear out over time, environments still vary, and failures still have physical causes, but the ability to anticipate and coordinate improves. Modern AI-assisted tools can support the unexperienced worker to perform as skilled workers.
One of the biggest misconceptions is that AI is primarily a technology project. In reality, it is often a data and operating model project. If data is inconsistent, supporting data is outdated or irrelevant, and sensor data is not trusted, AI will simply scale the same uncertainty.
“If the foundations are not in place, AI does not create clarity, it multiplies ambiguity,” Vuopala said.
Organizations that succeed typically do the basics well: they have clear asset hierarchy and criticality classification, consistent failure modes and coding practices, disciplined work order routines, and reliable instrumentation. AI can help clean and structure data, but it cannot compensate for missing context.
“Maintenance knowledge, such as what happened, why it happened, and what was done, still needs to be captured,” Vuopala adds.
Even a strong model is useless if people do not trust it. For maintenance teams, trust is built when AI outputs are understandable enough to be validated, consistent over time, linked to real operational outcomes, and integrated into everyday workflows, planning routines and daily meetings.
AI hallucinations instantly destroy trust. Therefore, it is important that AI uses only factory and machinery specific data and documentation, work and maintenance instructions and other up-to-date available and relevant documentation. “Explainability and clear workflows empower the worker and turn analytics into action,” Vuopala said.
Combatting the skills shift: In many established industrialized countries, ageing workforces and retirements are an issue. The loss of tacit knowledge poses a real threat to cost-efficient operations.
Younger generations have, however, grown up with smart devices. With AI-supported workflow creation, including easy-to-use enhancement and commenting features, both user groups can be served with clear work instructions. At the same time, critical tribal knowledge can be captured and used to continuously improve workflows and site-specific process instructions.
“The goal is not to turn technicians into data scientists, but to make AI a practical tool that supports expert judgement, work safety and doing things right the first time,” Vuopala said.
As maintenance becomes more connected, cybersecurity and governance move from background topics to frontline concerns. OT environments have long lifecycles, and introducing new analytics layers must not compromise safety or uptime. Clear governance answers practical questions: who owns the data and who can use it, how models are updated and validated, what happens when recommendations conflict with local experience, and how decisions are documented for continuous improvement.
So, does everything change? No. The fundamentals of maintenance remain: asset knowledge, disciplined execution and continuous improvement. What changes is the speed of situational analysis, the quality of decisions, and the capability to act quickly on the factory floor, when AI is implemented with the right foundations.
“AI provides a tool to empower your workforce with capability you build on data quality, reliability practices and cross-functional collaboration,” Vuopala concludes.
According to Vuopala, ABB is currently implementing its new AI-assisted maintenance tools, Industrial Knowledge Vault, at its global customer base. For example, ABB is working with a European mining company on procedure dispatches for their mine hoist inspections and work tasks. Another example case is a major Indian battery materials company taking these new tools into use.
Text: Mia Heiskanen
Subscribe to the free Maintworld newsletter here!
The Future of Asset Management: Where People and Technology Must Converge

Why the Future of Asset Management is about People as much as Technology? Maintenance and Asset Management are entering a decisive decade. According to the NVDO Maintenance Compass 2025, the sector faces a convergence of major developments: rapid digitalisation, a growing shortage of experienced technicians, and increasing pressure from the energy transition and sustainability goals.
We spoke with Ellen den Broeder-Ooijevaar, General Manager of the Dutch Maintenance Society, NVDO, about the key insights from the research and what they mean for organizations responsible for maintaining critical assets. “Maintenance has always been about reliability and continuity,” she explains. “But the context in which we operate is changing dramatically. Technology, workforce dynamics and societal expectations are all evolving at the same time”.
The Loss of Craftsmanship in the Age of Automation. One of the most striking findings in the NVDO research concerns the labour culture in Maintenance. What is happening according to the recent Dutch Maintenance Compass?
Den Broeder: “We see a clear shift. Traditionally, Maintenance relied heavily on craftsmanship passed down from generation to generation. Many technicians learned their trade through experience on the shop floor. But that type of knowledge transfer is under pressure”.
According to NVDO’s findings, many experienced professionals are approaching retirement while fewer young technicians enter the field. “This creates a knowledge gap,” Den Broeder says.
“When craftsmanship disappears without being properly transferred, organizations become vulnerable in terms of quality, safety and operational continuity.”
At the same time, the expectations of the younger workforce are different. “Young professionals want flexibility, autonomy and meaningful work. Organizations therefore need to rethink how they attract, develop and retain talent in Maintenance.”
Digitalisation is changing the game. At the same time, technology is evolving rapidly. How does digitalisation affect Maintenance according to NVDO’s Maintenance Compass?
Den Broeder: “Digitalisation is transforming Maintenance into a much more data-driven discipline. Sensors, predictive analytics and digital platforms allow us to monitor assets continuously and anticipate failures instead of reacting to them.”
This shift fundamentally changes the role of Maintenance professionals. “In the past, Maintenance was often reactive. Today, the goal is predictive and strategic Asset Management. That requires different competencies: data interpretation, systems thinking and collaboration across departments.”
However, she emphasizes that technology alone is not enough. “Digital tools are powerful, but they must be embedded in the right culture and processes. Without skilled people who understand both the assets and the data, digitalisation will not deliver its full value.”
Maintenance in the Age of Sustainability. Sustainability also plays an important role in the NVDO research. How does Maintenance contribute to that transition?
“Maintenance is actually a crucial enabler of sustainability. Well-maintained assets consume less energy, operate more efficiently and last longer. That directly contributes to climate goals and circularity.”
Organizations increasingly recognise that Asset Management is not just about reliability and cost control, but also about environmental impact. “Extending the lifetime of installations, improving energy efficiency and preventing unnecessary replacements all contribute to a more sustainable industry.” In other words, Maintenance has moved from a supporting role to a strategic one. “Asset Management is now directly linked to corporate strategy.”
From Maintenance Department to Strategic Function in Modern Asset Management. Another important conclusion from the NVDO Maintenance Compass is the growing strategic importance of Maintenance within organizations.
“Historically, Maintenance was often seen as a cost centre,” Den Broeder explains. “But leading organizations increasingly recognise it as a value driver.” Reliable assets are essential for productivity, safety and sustainability. As a result, Maintenance professionals are becoming more involved in strategic decision-making. “We see Maintenance leaders participating in boardroom discussions about asset strategy, risk management and long-term investments. That is a major step forward for the profession.”
The Human Factor Remains Crucial in an Increasingly Digitalised Maintenance Environment. Despite the rise of digital technologies and data-driven approaches, Den Broeder stresses that people remain at the heart of Maintenance.
“Technology can support us, but craftsmanship and expertise are irreplaceable. The challenge is to combine traditional knowledge with new digital capabilities.”
This is why NVDO focuses strongly on education and knowledge development. “We work closely with industry, education and government to strengthen the Maintenance profession. Initiatives such as learning programmes and knowledge platforms help professionals develop the skills needed for the future.”
Collaboration Across the Ecosystem. Another trend highlighted in the research is the growing need for collaboration. Maintenance challenges are becoming more complex and often extend beyond the boundaries of a single organization.

“Supply chains are more interconnected than ever,” Den Broeder says. “Maintenance performance increasingly depends on collaboration between asset owners, service providers, technology suppliers and knowledge institutions.”
Sharing knowledge and best practices therefore becomes essential. “That is exactly the role NVDO aims to fulfil: bringing together professionals from different sectors to exchange insights and accelerate innovation.”
If you look ahead, what will determine success in Maintenance and Asset Management? Den Broeder does not hesitate. “The organizations that succeed will be those that balance technology with human expertise.” They will invest in digital tools, but also in people. They will treat Maintenance not as an operational necessity, but as a strategic capability. “And above all, they will understand that reliability, sustainability and innovation are closely connected.”
She concludes with a clear message; “Maintenance is no longer just about fixing things. It is about managing assets intelligently, sustainably and strategically. That makes our field more important than ever.”
Key Signals from the NVDO Maintenance Compass
• A significant shift in labour culture and a shortage of experienced technicians
• Rapid digitalisation of Maintenance and Asset Management
• Increasing importance of sustainability and energy efficiency
• Growing recognition of Maintenance as a strategic business function
• Stronger need for collaboration across the industrial ecosystem
About the Author:

Ellen den Broeder-Ooijevaar, General Manager NVDO; “The biggest transformation in Maintenance is not only digital. It is cultural. Organizations must rediscover craftsmanship while embracing data-driven Asset Management”
Subscribe to the free Maintworld newsletter here!
Stop Pushing Change, Remove the Brakes Instead

Why do so many improvement initiatives stall, even when the benefits seem obvious? According to marketing professor and bestselling author Jonah Berger, the problem is not that people resist change. The problem is that organizations try to push harder instead of removing the barriers that hold people back.
In maintenance and asset management, leaders constantly introduce new ideas: predictive maintenance, digital tools, new work processes, or safety improvements. Yet even well-planned initiatives often struggle to gain traction.
Meetings are held, strategies are communicated, incentives are created. Still, people continue working the way they always have.
The instinct is to push harder with more communication, more pressure, more persuasion. But Berger argues that this approach rarely works. Instead of pushing people toward change, effective leaders act as catalysts. They focus on removing the obstacles that prevent change from happening in the first place. This idea is captured in the REDUCE framework, which identifies five common barriers that slow down or stop change.
The REDUCE Framework highlights five “parking brakes” that hold organizations in the status quo:
Reactance
When people feel pushed, they push back. Instead of telling teams what to do, leaders should give them agency. Asking questions or offering choices often works better than issuing directives.
Endowment
People value what they already have. Even if a new system is better, the current process feels safer and familiar. Successful change leaders highlight the hidden costs of staying the same and make switching easier.
Distance
If a proposed change feels too radical, people reject it outright. Breaking change into smaller steps can bring it closer to people’s comfort zone.
Uncertainty
People hesitate when outcomes are unclear. Pilot projects, trials, and demonstrations can reduce the risk people feel when trying something new.
Corroborating Evidence
One voice is rarely enough. Change spreads faster when people hear similar messages from multiple trusted sources across the organization.
What This Means for Maintenance Leaders. Maintenance organizations often operate under pressure: reliability targets, cost control, safety requirements, and digital transformation. In such environments, it is tempting to drive change quickly through mandates. But catalysts take a different approach. Before launching the next initiative, ask a different question: What is stopping people from changing already?
Maybe technicians are uncertain about a new predictive maintenance tool. Maybe planners believe the current system works well enough. Or maybe the change feels too large to adopt all at once.
Identifying these “parking brakes” allows leaders to remove friction instead of adding pressure.
The key lesson from Berger’s work is simple: people rarely change because they are persuaded. They change when barriers disappear.
In maintenance organizations, where experience and established routines run deep, this insight is especially valuable.The next time an improvement initiative slows down, resist the urge to push harder. Instead, look for the brakes.
Author bio
Jonah Berger is a professor at the Wharton School of the University of Pennsylvania and an internationally bestselling author. His book The Catalyst: How to Change Anyone’s Mind explores why change is difficult and how leaders can remove the barriers that prevent it.
Text: Mia Heiskanen
Photo: Pasi Salminen
Subscribe to the free Maintworld newsletter here!
Labour Shortages Now a Structural Risk to Workplace Safety, EU-OSHA Warns
Europe’s labour shortages are hardening into a long-term structural challenge, and they are increasingly intertwined with workplace safety risks, according to a new analysis from the European Agency for Safety and Health at Work (EU-OSHA).
The agency’s findings suggest that an ageing workforce, rapid technological change and the green transition are reshaping labour markets in ways that intensify staffing gaps across nearly all sectors.
While healthcare, ICT and skilled trades remain the most visibly affected, EU-OSHA notes that few industries are untouched. And the consequences extend far beyond unfilled vacancies.
When teams shrink, the remaining workers often face heavier workloads, faster work pace, longer hours and more irregular schedules. These pressures heighten exposure to musculoskeletal strain, accidents and psychosocial stress – conditions that can push even more workers out of the labour market.
EU-OSHA describes this as a “tightening feedback loop”: shortages worsen safety and health conditions, and deteriorating conditions make it harder to recruit and retain staff. Poor occupational safety and health (OSH) performance becomes not just a symptom of labour scarcity, but a driver of it. Organisations that invest in strong OSH systems—clear procedures, ergonomic design, predictable schedules, supportive management—tend to retain workers more effectively and attract new ones even in competitive labour markets.
Prevention, the agency argues, is no longer just a compliance obligation; it is a competitive advantage.
The analysis outlines several channels through which OSH can strengthen labour supply. Safer workplaces reduce early exits due to injury or illness. Better working conditions improve the appeal of sectors struggling to recruit. Jobs designed for older workers and proper rehabilitation help people stay in work longer. At the same time, clear safety training helps new workers become productive faster without increasing the risk of accidents.
EU-OSHA also warns that poorly designed responses to shortages can backfire. Accelerated recruitment, compressed training or excessive overtime may ease short-term pressure but often increase long-term risks to workers and productivity.
To avoid this, the agency calls for OSH considerations to be embedded directly into labour shortage strategies at company, sector and policy levels.
For workplace safety professionals, this means explicitly accounting for understaffing, fatigue and time pressure in risk assessments. It also requires maintaining robust onboarding systems, ensuring training is not skipped, and monitoring psychosocial risks such as stress and burnout. Indicators like overtime levels or sickness absence can serve as early warning signs of overload.
Worker representatives, EU-OSHA notes, play a crucial role in ensuring that chronic understaffing does not erode protections. Treating persistent shortages as a safety hazard, safeguarding the voluntary nature of extra work and protecting the right to refuse unsafe tasks are highlighted as essential. Tight labour markets also give representatives leverage to push for improvements in job quality that support retention.
Employers, meanwhile, are encouraged to compete not only on wages but on overall job quality. Predictable hours, ergonomic workplaces, clear career pathways and consistent safety practices are all cited as key retention tools. Even under staffing pressure, safety checks, equipment maintenance and supervision must be preserved. An open safety culture—where workers feel able to report risks—is described as indispensable.
At policy level, EU-OSHA urges national governments and EU institutions to integrate OSH indicators, such as injury rates or burnout levels, into labour shortage strategies with clear targets.
Investments in labour inspectorates, training systems and data collection should explicitly consider their impact on workforce participation and productivity. Public procurement and social dialogue are identified as important levers for spreading good practice.
Labour inspectorates are encouraged to focus enforcement where shortages are most acute, ensuring that working time rules, training requirements and safety procedures are not eroded under pressure. Better use of data and closer cooperation with social partners are seen as essential for identifying systemic risks early.
In short, the European Agency for Safety and Health at Work views workplace safety as an economic strategy: improving safety helps retain workers, attract new talent, and boost productivity, especially in times of labour shortages.
ELA report – Key highlights for manufacturing
• Skilled trades are at the centre of labour shortages in manufacturing, with roles like welders, machinists and machine operators consistently hard to fill. According to the European Labour Authority, these shortages have remained unchanged for years, pointing to a structural problem.
• Demand for skilled workers remains high despite digitalisation and the green transition, meaning the need for experienced workers on the shop floor is not going away.
• Labour shortages increase pressure on existing staff, who often have to take on more tasks, run multiple machines or work longer hours—raising safety risks in already demanding and hazardous environments.
• Improving job quality is essential: better training, safer workplaces and clear career paths can help attract and retain workers, while a lack of improvements will likely keep shortages in place long term.
(Labour shortages and surpluses in Europe 2024, ELA)
Text: Nina Garlo-Melkas
Subscribe to the free Maintworld newsletter here!
Reliability Is Built by People

Industrial maintenance is undergoing a major transformation. Artificial intelligence and today’s highly advanced technologies have made real-time condition monitoring almost routine. AI-driven solutions are being piloted at an accelerating pace, and more data is being collected than ever before. It is easy to believe — and to convince ourselves — that technology alone will solve the future challenges of maintenance.
Yet amid this technological enthusiasm, it is important to remember one fundamental truth that has not changed: reliability is still built by people. Our journalist Mia Heiskanen interviewed Maroua Ouerghemmi, Senior Manager for the United Kingdom and the Nordics at The Coca Cola Europacific Partners CCEP, for this issue’s cover story. In the article, Ouerghemmi captures the essence of the matter perfectly. According to her, trust, clarity, and the ability to turn strategy into everyday actions are just as important as the most advanced analytical tools. Without these elements, technology easily remains disconnected from daily operations — the potential exists, but the impact falls short.
Maintenance is not only about processes and systems; above all, it is about collaboration between people. Trust is built in everyday work: in how information is shared, how mistakes are handled, and how decisions are made. Clarity means that everyone understands their role and objectives. Only then can broad strategies be transformed into practical actions on the factory floor.
The maintenance environment is often demanding and high-pressure, and success requires the ability to understand the people behind the numbers. The best leadership is ultimately about leading people.
Communication between professionals cannot be one-directional. It must be based on dialogue, interaction, and flexibility for everyone involved in the process. Empathy is not merely a soft addition to leadership; when applied correctly, it can become a genuine competitive advantage. It improves engagement, communication, and ultimately operational reliability.
A company may have the world’s best ERP systems, cutting-edge technology, and advanced AI tools, but if its people are not committed to the company’s story, values, and goals, much of it becomes meaningless. People create the results.
The human dimension becomes even more important in today’s modern and diverse workplaces. Factories now employ professionals from all over the world, and a single production facility can become a true melting pot of cultures.
This should not be seen as a challenge, but as an opportunity. During the construction of the West Metro project in Finland (2009–2017), infrastructure professionals from as many as 33 different countries worked together. This kind of diversity enriches expertise in ways that cannot easily be achieved otherwise.
In the future of maintenance, the winners will be the organizations that combine the possibilities of technology with a strong human foundation. Data can tell us what is happening — but people decide what will be done about it.
Jari Kostiainen

Subscribe to the free Maintworld newsletter here!
Latest





